[Paper review] Eyeriss: An Energy-Efficient ReconfigurableAccelerator for Deep
해당 paper에 대해서 공부한 내용을 정리해보려고 합니다.
Ⅰ. Problem & Purpose
ⅰ. Problem
- CNN Model은 Throughput과 Energy 관점에서 문제점이 존재
- 많은 데이터를 요구하는데, 이를 위해서 on-chip과 off-chip 사이 data 이동이 상당히 많음
- Off-chip memory에서 data(filter, input, partial sum)값을 읽어서, MAC 연산 후 다시 Memory write
+ 많은 에너지 소모를 발생 시킴
(※ 핵심은 data의 이동을 최소화 시킨다면, 에너지 소모를 줄일 수 있다는 것입니다. )

- Paper에서는 Alexnet 경우에는 724M MAC 연산과 2896M DRAM 접근이 필요하다고 합니다.
+ 많은 연산으로 인해서 많은 에너지 소모를 하기 때문에, DRAM Access를 하는 걸 최대한 줄여서 에너지 소모를 줄이는 것이 필요하다는 것이죠

ⅱ. Purpose
- DRAM Access를 줄이기 위해서는 단순하게 생각해볼수 있는 것이 중간에 큰 on-chip buffer를 배치하는 것이겠지요. 해당 논문에서 그렇게 말을 하고 있습니다.
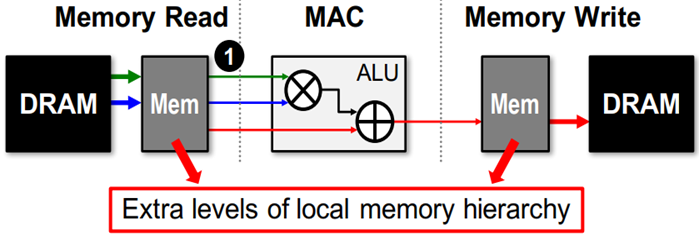
- 그러면 이러한 질문이 있을 수 있습니다.
+ "local memory"에 접근할 때에도 에너지 소모가 있는데 이는 괜찮은가?
+ 정답은 "상대적으로 YES"입니다.
+ 아래 그림을 보시면, 각 종 메모리로부터 ALU(Arithmetic and Logical Unit,)(*여기서는 MAC 연산기라고도 뭐 할수 있을 것 같네요.)까지 DATA를 가지고 오는데 소모되는 에너지 Cost를 나타낸 것입니다.
+ 정확히 내용은 몰라도 수치만 보아도 DRAM 에서 가져오는 것이 다른 메모리부터 가져오는 것 보다 많은 에너지를 소모하는 것을 볼 수 있습니다.
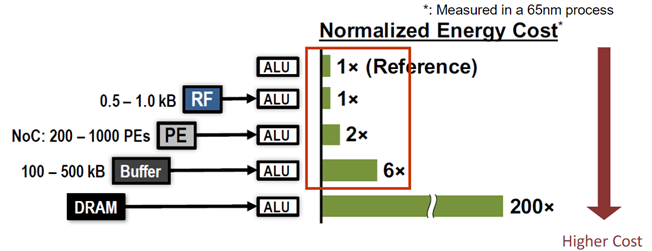
- 그러면 또 이러한 질문이 있을 수 있습니다.
+ "Local memory만 사용하면 되는 것이냐?"
+ 정답은 "no"입니다.
+ 해당 논문에서는 "Local memory"를 사용하면서, Local memory 로 가져온 data들을 최대한 재사용(reuse)하는 동시에 partial sum data를 가져오기 위한 dram access 하는 것을 없애기 위해 local memory 내에서 accumulation 하여야 한다고 하였습니다.
> 해당 논문에서는 3가지 reuse에 대해서 설명하였습니다.
→ Convolutional reuse / Image reuse / kernel reuse
- 또한, memory hierarchy를 가지며, data movement를 최소화 할 수 있는 구조로 설계되어야 한다고 하였습니다.
+ 추가적으로는 실질적으로 계산하는 PE(Processing Element)는 최대한 IDLE 상태가 되지 않게끔 하도록 해야한다고 하였습니다.
Ⅱ. Contribution
- DNN(Deep Nerual Network)의 Data flow Taxonomy (3개의 카테고리)
+
- Row-Stationary(RS) Dataflow 제안
+ energy 측면에서, 기존 data flow보다 1.4 ~ 2.5 배의 정도 효율적임
- Hardware architecture(*eyeriss ver.1)
+ RS Dataflow를 이용하여, data reuse를 최적화
+ 전체적인 energy cost를 줄임
+ Flexible mapping 방법을 통해서, PE의 utilization을 향상시킴
+ NoC(Network on Chip) 구조 기반으로 Multicast를 가지고 몇몇개의 pattern을 전달함
> broadcast 보다 energy cost가 적음
+ Run length compression(줄 길이 압축)을 통해서, data 크기를 줄였기 때문에 energy 소모 ↓
( 앞에 내용들에 비해서는 엄청 대단한 contribution은 아닌듯한 느낌입니다. )
설명하기 전에 parameter 정의는 아래와 같습니다.

- N : Batch size
- M : 3D 필터의 수 혹은 Ouput feature map의 채널 수
- C : Input feature map / Filter의 채널 수
- H/W : Input feature map의 height/width
- R/S : filter feature map의 height/width
- E/F : output feature map feature map의 height/width
Ⅲ. 전체적인 하드웨어 구조
- 아래의 그림은 전체 top-level의 구조를 보야주고 있습니다.
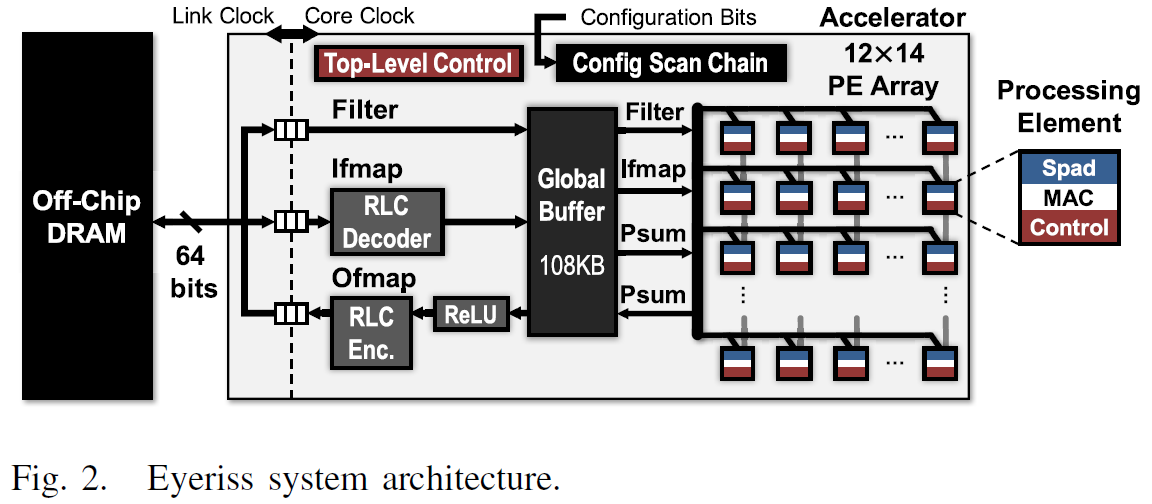
- 2개의 clock domain이 있습니다.
+ Processing을 위한 core clock domain과 64bit data bus를 가지고 Off-chip과 Communication을 위한 link clock domain이 존재
+ Two domain은 독립적으로 동작하고, Asynchronous FIFO를 통해서 Data를 주고 받음
+ Core clock domain은 12*14 matrix형태의 168개의 PEs, 108kB GLB(Global Local Buffer), RLC Codec, ReLU 모듈로 구성됩니다.
> NoC를 통해서, PE들은 GLB 혹은 이웃 PE들과 data를 주고 받습니다.
- memory hierarchy는 4 level로 되어 있습니다.
+ DRAM / GLB / inter-PE communication / spads(PE 내 레지스터)
- 가속기는 2 level의 control hieracky를 가짐
+ Top-level
> DRAM과 GLB 사이의 Traffic 제어
> NoC을 통해서 GLB와 PE array사이 Traffic 제어
> RLC 코덱 및 ReLU 모듈 동작
+ Lower-level
> 독립적으로 동작하는 각 PE 내에서 내부 control
+ 168개의 PE가 있지만, Processing 상태를 기다리지 않고 필요한 정보 (feature map or partial sum 등)가 입력되면 바로 Processing 시작(※ systolic array 가 아님)
Ⅳ. CNN 관련 내용, ENERGY-EFFICIENT FEATURES
ⅰ. Common CNN 연산
- 일반적으로 CNN 연산은 아래와 같이 이루어집니다.
+ 아래 그림을 보시고, 이해가 안간다면 하기 포스팅 참고 부탁드립니다.
CNN(Convolution Neural Network )
이제 영상처리 뿐만 아니라 다른 분야에서도 막대한 영향을 끼친 CNN에 대해서 정리해보고자 합니다. Ⅰ. CNN(Convolution Neural Network) - CNN(Convolution Neural Network)는 이미지 인식 분야에서 많이 활용되
honeybee0103.tistory.com
CNN 연산량 줄이는 scheme
이전 포스팅에서 CNN을 다루었는데, 직감적으로 아시겠지만 영상이 커지거나 필터의 수가 무수히 많거나 Layer가 매우 깊다면 연산량은 매우매우 많아지게 됩니다. 그래서 연산량을 조금이라도
honeybee0103.tistory.com
CNN - Image2col / reshape
제가 공부를 하고 있는 책에서는 두 개의 함수를 통해서, 연산을 수행하고 있습니다. 하지만 이 책에서만 그렇게 하는 것이 아니라 인터넷에서 정보를 찾아보니 대부분의 딥러닝 프레임워크에
honeybee0103.tistory.com
+ 짧게만 설명을 드리겠습니다.
> 빨간색 네모와 선은 Filter feature map의 경우 (R*R*C) 하나가 Input image의 한 부분(R*R*C 만큼)과 Convolution 연산 후, output image의 하나의 채널 내 하나의 픽셀로 맵핑되는 것을 의미합니다.

ⅱ. DATA Reuse
- 앞서 말씀드렸듯이, DRAM에서 가져온 DATA를 최대한 재활용(Reuse)하여야 합니다.
- CNN의 경우에는, 아래와 같이 재활용이 가능합니다.

1. Convolutional resue
- Convolution layer에서만 적용 가능합니다.
- CONV. Layer에서는 1개의 filter가 1개의 input image(or feature map)을 sliding 하면서, output feature map을 출력합니다.
+ 아래의 그림과 같이 conv. 하나의 filter 는 하나의 input image만을 sliding을 하면서 output 계산합니다.
(*최종적으로는 sum이 되겠지만요.)
- Local memory에 있는 Input image data와 Filter kernel data를 최대한 재사용하자는 것이 핵심입니다.
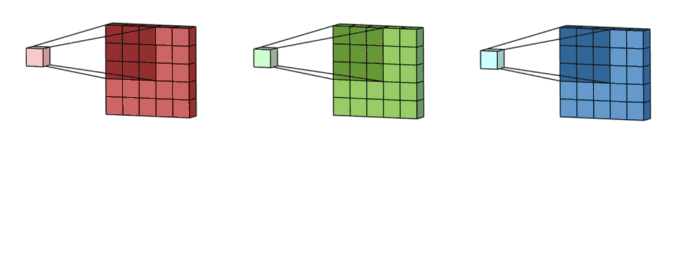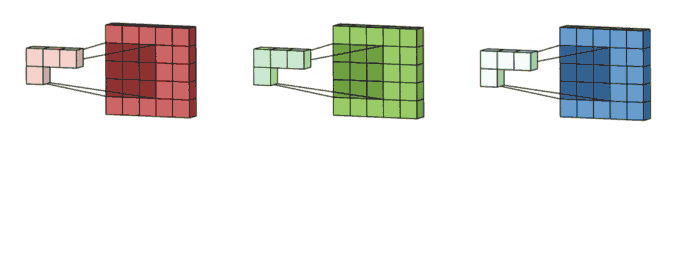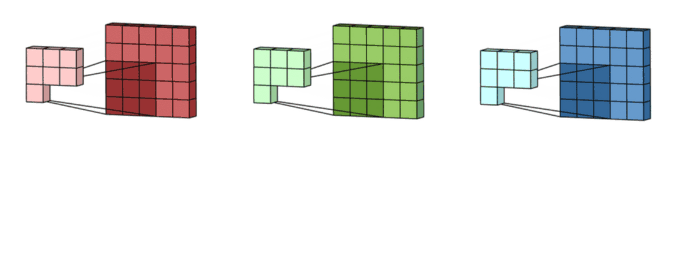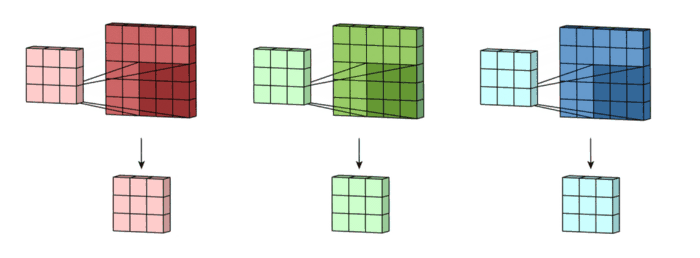
2. Image reuse
- Convolution layer와 Fully Connected layer에서 사용 가능합니다.
- Input image(H*H*C) 들은 Filter kernel(R*R*C)들의 set(M개)들과 연산을 수행합니다.
+ 이때 input image들은 동일하게 재사용 될 수 있습니다.
- Local memory에 있는 Input image data를 최대한 재사용하자는 것이 핵심입니다.

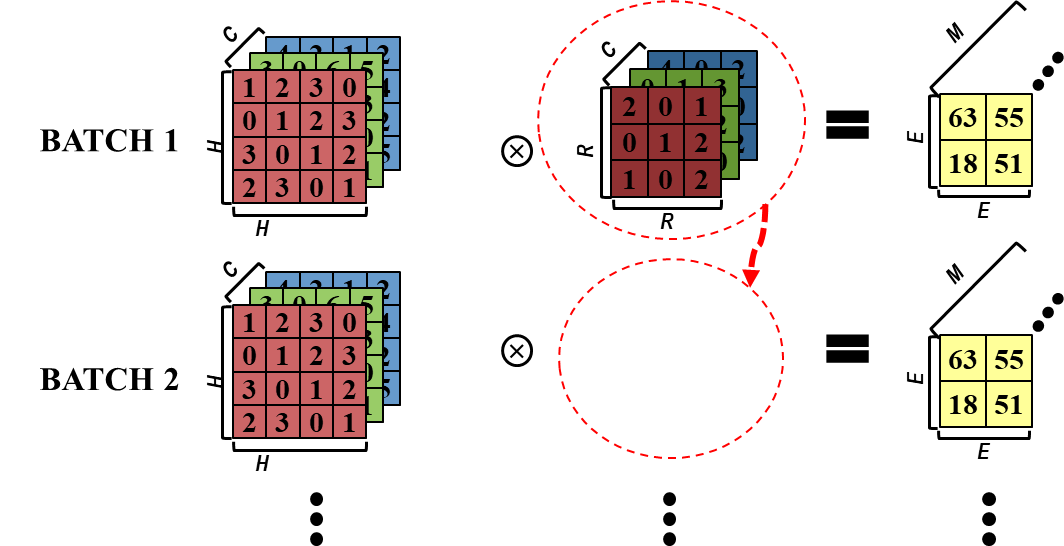
3. Filter resue
- Convolution layer와 Fully Connected layer에서 사용 가능합니다. 또한, Batch size가 2 이상일 때, 적용 가능합니다.
- 1개의 Filter kernel(R*R*C) set은 여러 Batch image 들에 공통적으로 사용됩니다.
+ 이때 Filter kernel set들은 동일하게 재사용 될 수 있습니다.
- Local memory에 있는 Filter kernel data를 최대한 재사용하자는 것이 핵심입니다.
ⅲ. Energy-Efficient Dataflow: Row Stationary(RS)
- 계산하여야 하는 CNN을 Hardware PE array에 mapping 하는 효율적인 방법을 제안
- RS dataflow는 모든 data( input feature map data, filter data, output feature map data)에 대한 data 이동을 최소화할수 있음
- spad와 PE간 Communication을 통해 data를 reuse를 최대화하여서 DRAM과 GLB 간 data 이동을 최소화 가능
1. 1D Conolution primitive (PE 내에서)
- 각 primitie들은 filter weight의 1 row와 input feature map의 1 row를 가지고 동작하며, partial sum 1 row를 계산해내게 됩니다.
- 해당 논문에서 아래의 예시로 설명을 잘해두었다.
+ Filter weight row는 sliding 되어 들어오는 input feature map과 convolutuon 연산되어 partial sum을 출력한다,
> 1*1 + 2*2 + 3*3 = 1
> 1*2 + 2*3 + 3*4 = 2
> 1*3 + 2*4 + 3*5 = 3

- 각 PE는 convolution data resue와 Partial sum accumulation을 위한 내부 scrach pad를 사용
→ PE 내 작은 메모리를 사용
+ 해당 예시는 Scrach pad의 size는 오직 filter의 row size(S)에만 의존적
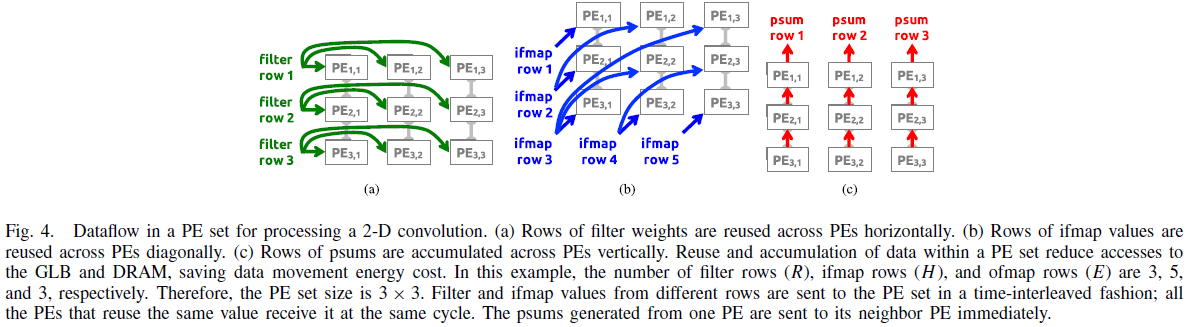
2. 2-D Convolution PE Set
- 2D Convolution은 많은 1-D convolution primitives로 구성된다.
- 같은 filter weight 혹은 input feature map을 공유
- 여러 계산 결과로부터 partisum을 accumulate
- 해당 논문에서 아래의 예시로 설명을 잘해두었습니다.
+ 3*3 PE set이 아래와 같이 있다고 가정
+ (a) 그림처럼 filter weight의 경우, filter weight의 row를 horizontal 방향으로 배치
+ (b) 그림처럼 input feature map의 경우, input feature map의 row을 diagonal 방향으로 배치
+ (c) 그림처럼 partial sum의 경우, vertical 방향으로 sum을 수행
+ 해당 예시를 아래와 같이 표시하는 것도 가능합니다.

+ 여기서 중요한 점을 다시 정리하면 아래와 같다.
> Filter row는 horizontal 방향으로 재사용됨
> Image row는 diagonal 방향으로 재사용됨
> Partial sum은 vertical 방향으로 accumulate됨
> 재사용을 통해서 최대한 GLB과 DRAM 사이의 data access을 최소화
- 추가적으로 PE내에서 data reuse 하는 방법을 설명하고 있습니다.
+ 아래 그림과 같이 image set이 2개가 있더라도 필터는 그대로 똑같이 사용되기 떄문에 filter data를 그대로 사용 가능합니다.
→ PE 내에서 Image row data를 concatenate 합니다.

+ 아래 그림과 같이 filter가 여러 set이 있지만, 동일한 image이 적용이 되기 때문에 image data를 그대로 사용 가능합니다. → PE 내에서 filter row data를 interleave 합니다.

+ 채널이 2 이상일 때, 채널 별로 interleae 된 filter data와 image data를 연산하여 계산된 partial sum 값들을 sum할 수 있습니다.

- 앞서 이야기한 재사용에 대한 이야기를 정리하면, 아래의 그림으로 표현이 가능합니다.

Ⅴ. PE Set과 PE Array mapping
- PE set의 size는 filter weight의 row와 output feature map의 row에 의존적입니다.
+ PE set의 height 는 filter weight row(R)과 같고, width 는 output feature map의 row(E)와 같습니다.
+ 예로 AlexNet의 경우, PE set의 사이즈는 11x55(CONV1), 45x27 (CONV2), 3x13 (CONV3–CONV5) 입니다.
- PE set =! PE Array, 두 개의 dimension에 대해서 맵핑을 하여야함
+ PE set : layer의 shape가 functional하게 동작하는 dimension을 명시
+ PE Array : 물리적인 dimension을 명시
+ 맵핑은 data sharing 과 partial sum accumulation을 잘하도록 맵핑
+ 예외의 CASE
> PE set > PE의 갯수 168개
① strip mining 이란 방법으로 해결 (※ 아래에서 설명)
strip-mined PE set width은 전체적인 enerdy 효율을 최적화 하기 위한 process에 의해 결정됨
> PE set < PE의 갯수 168개. Width >14 혹은 Height > 12
① PE set을 몇개의 segment로 나눔
② Eyeriss의 경우, Height가 큰 경우는 지원 x (※ 즉, filter height의 최대 크기는 12)
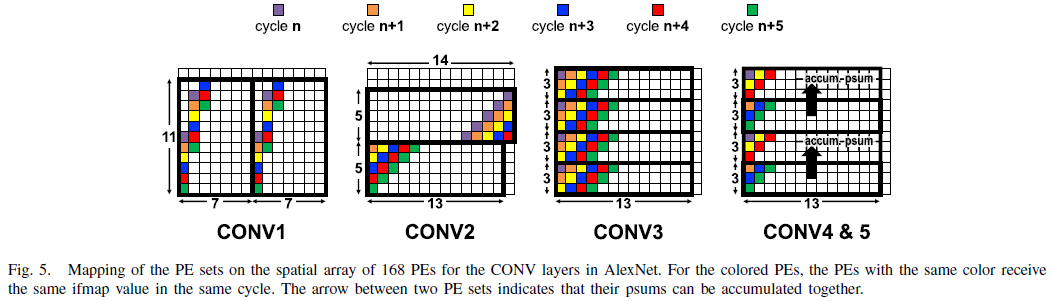
+ 이제부터는 AlexNet을 기준으로 mapping을 어떻게 하였는지 보겠습니다.
> 해당 논문에서 아래의 예시로 설명을 잘해두었습니다.
> AlexNet의 경우, PE set의 사이즈는 11x55(CONV1), 45x27 (CONV2), 3x13 (CONV3–CONV5)
① CONV1 : 11x55 PE set은 11*7 형태로 strip-mining
초록이 4칸 차이가 나는 것은 stride가 4 이기 때문입니다.
② CONV2 : 45x27 PE set은 5*14 + 5*13 형태로 strip-mining
③ CONV3-5 : 3x13 PE set은 PE array에 fit함
아래의 그림에서 나누어져 있는 이유는 CONV3에서는 Input이 4개의 set에 전달되지만
CONV4-5 에서는 같은 input이 2개 2개 set에 전달됩니다,
CONV3의 경우 PE Array에 ROW 내 13 pixel에 대해서 4개의 filter를 도이에 적용

※ p : filter의 수, q : 채널의 수
ifmap scrach pad 크기는 오직 1 row 를 저장할 수 있는 크기
filter scrach pad 크기는 (필터의 수 * 채널의 수 )만큼 저장할 수 있는 크기
partial sum scrach pad 크기는 ifmap에 2배 크기