Ⅰ. Batch 단위 학습의 문제점
- SGD의 경우, Batch 단위로 학습을 진행하게 됩니다. 이때 발생하는 문제가 ‘internal covariant shift’이며, 이를 해결하기 위한 방법이 "Batch normalization" 입니다.
+ internal covariant shift : learning 과정에서 layer 별로 입력의 데이터 분포가 달라지는 현상을 말합니다.
- Batch 단위로 학습을 하게 되면 Batch 단위 간에 데이터 분포의 차이가 발생하는데, 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것입니다.
+ 분포를 zero mean gaussian 형태로 만듭니다.
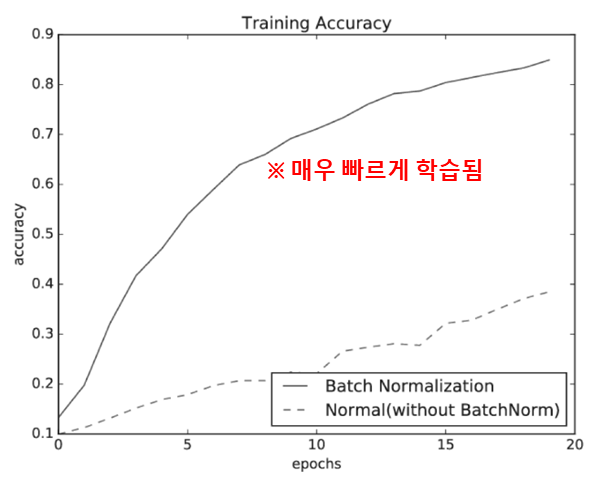
- 아래의 그림을 보시면 바로 이해가 되실겁니다.

Ⅱ. Batch nomalization
- 각 Layer 마다, activation value 값을 적당히 분포되도록 조정합니다.
- Learning 시, mini-batch 단위로 정규화(normalization)을 수행하며 데이터의 분포가 평균이 0, 분산이 1이 되도록 정규화 합니다.
- Batch Normalization은 Activation function 전에 삽입되며, Learning 과 Inference 에서 다르게 적용됩니다.
+ 해당 내용은 아래의 블로그에서 매우매우 상세히 잘 설명해놓으셔서 링크를 남길테니 참고하세요!
(※ https://gaussian37.github.io/dl-concept-batchnorm/ )
- 그러면 Batch normalization을 왜 사용하느냐.
+ 학습 속도 개선이 가능합니다.
+ 초기값 설정의 의존성 ↓
+ Overfitting 억제하며 gradient vanishing 문제 방지할 수 있습니다.
i. Batch nomalization 수식
- 수식은 아래와 같이 정의됩니다.

+ μ_B : 입력데이터의 집합에 대한 평균
+ σ_B^2 : 입력데이터의 집합에 대한 분산
+x ̂_i : 평균이 0 이고, 분산이 1인, 변환된 데이터
+ ε : 매우 작은 상수 값 (Zero-division 방지)
+ γ와 β는 Batch normalization을 통해, layer 마다 normalization 된 데이터에 scale(확대) 및 shift(이동)을 수행합니다.
> γ 와 β는 초기에 1과 0으로 설정되며, 학습하면서 조정합니다.
> γ : 확대를 담당
> β : 이동을 담당
+ Batch normalization은 Batch의 크기에 영향을 많이 받는 단점이 있습니다.
> 너무 적으나 혹은 너무 많으면, 제대로 동작 X
Ⅲ. CNN(Convloution Neural Network)에서의 batch nomalization
- CNN 에서는 수식이 조금 달라집니다.
+ Fully connected layer 에서는 각 neuron별로 정규화
+ Convolution layer 에서는 각 채널별로 정규화
- Batch, Height, Width에 대해 평균과 분산을 계산
(※ 해당 내용도 위에서 언급한 블로그에서 읽은 내용을 가져온 것입니다!)

'Digital Hardware Design > Deep learning' 카테고리의 다른 글
| CNN 연산량 줄이는 scheme (0) | 2022.11.23 |
|---|---|
| CNN(Convolution Neural Network ) (0) | 2022.11.23 |
| weight 설정 (0) | 2022.11.23 |
| Weight optimization (0) | 2022.11.23 |
| 학습(Learning) & 손실함수(Loss function) & 역전파(Backpropagation) (0) | 2022.11.22 |




댓글